A basic and sensitive need of HIEs today is to eliminate duplicate patient admissions. It is important to identify, link and locate correct patient record in HIE.
Let's walkthrough a very basic patient matching implementation. This shall provide you an overview of big picture.
HL7 Identifier Hierarchy plays important role in this.
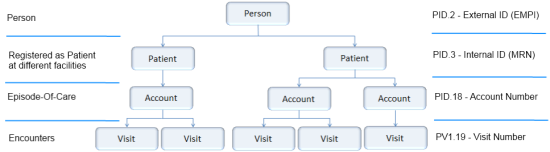
A detailed explanation is available in this article Identifier Hierarchy
Let’s consider a sample HIE implementation, where HIE is connected with two source systems, Hospital A and Hospital B
Now suppose Patient John Smith is registered in Hospital A with following demographics
| MRN | First Name | Last Name | Gender | DOB | Street1 | SSN | Insurance Policy# |
| HA1234 | John | Smith | M | 07/21/1975 | 105th Ave | 435-343-565 | 33253453 |
HL7 message will be sent to HIE from Hospital A. Let's assume this patient is new in our HIE, so HIE will create a patient and assign it a unique Person Identifier (EMPI) which will identify all the records of this patient across healthcare facilities participating in HIE. The entire demographics data will be stored in separate repository which will be used for patient matching.
Now suppose John Smith visits Hospital B and registered here with following demographics
| MRN | First Name | Last Name | Gender | DOB | Street1 | SSN | Insurance Policy# |
| HB76454 | John | Smith | M | 07/21/1975 | 105th Ave | 435-343-565 | 33253453 |
HL7 message will be sent to HIE from Hospital B. Now, HIE will try to identify if this patient already exists. It will query its demographics repository. We will discuss matching functionality later in this article. For now let’s suppose we found the match and decided to link John Smith from Hospital B to existing EMPI (of John Smith from Hospital A). So HIE will now maintain two patients from two source systems but both of these will be mapped to single EMPI.
This way we can query John Smith’s all the data across healthcare facilities from HIE.
Now let’s discuss patient matching.
Before deciding to apply any match criteria, it is required to analyze data and decide which data elements can participate in matching.
Suppose, your source systems do not capture/send SSN then it is useless to include SSN in match criteria. Similarly let’s assume you receive SSN for very small percentage of the patient records then it is advisable to consider it with other strong match criteria and assign a very low weightage to SSN. This is one simple example and I just want to emphasize the importance of good data analysis for patient matching.
Master Repository
To start implementing patient matching, you need a repository where you will store demographics data of all the patient records. This repository should contain all the data fields that will participate in matching algorithm & will be decided in data analysis phase.It is very important to maintain uniform formatting while storing data values in repository. For example:
- Identify unique set of values for fields like Gender i.e. M,F
- Identify standard formatting for fields like SSN, Phone, Insurance Policy Number etc.
- Identify & exclude placeholder values like “UNKNOWN” for address, 1/1/1900 for DOB
- Exclude any record with test/temporary patient
Normalize your inputs
Before you call your matching algorithm you will have to prepare input parameters for it. These inpur parameters will be used by algorithm to run the matching rules. So format of your input parameters must match the format stored in repository.If you receive HL7 message with SSN as NNN-NNN-NNN and you store SSN in repository as NNNNNNNNN. In this case you will have to remove hyphens in SSN before you pass this value to algorithm.
We need to do this normalization on all the fields required for matching.
Data Exclusion
Similarly you also need to avoid dummy/placeholder values like- SSN: 000-000-000 or 111-111-111 etc.
- DOB: 1/1/1900
- Patient Name: Test
- Street Address: HOMELESS, UNKNOWN
- Phone: 000000, alphanumeric, Not 10 digits
Query Repository
After you have normalized all the data inputs, you will query the repository to find the match. This query should execute a set of rules in sequence to determine the best possible match for this patient.Once executed all the rules, this query should return you the match if found else you will treat this as a new patient.
Matching Rules
There could be many rules defined based on the analysis. One important thing is to decide the order in which these rules will be executed. You should have stronger match criteria executed first then go for others.Example Rules:
- First Name + Last Name + Gender + DOB + Street + SSN
- First Name + Last Name + Gender + DOB + Street + Home Phone + Insurance Policy
- First Name + Last Name + Gender + DOB + Street + Home Phone
Here are few interesting cases that I want to discuss. All of these are related to Incorrect or Out-of-Date Data in repository and a better algorithm can help improving matching rate.
-
Change in Address
- In this case we have receive an existing patient but there is a change in address, may be because patient has relocated
- Most of the data elements would be matching except the address. Home Phone can also differ in some cases.
-
Change in Name
- This is a case of change in Family Name after marriage
- We have this patient registered in HIE (before marriage) but data in repository is incorrect now.
- In this case patient’s last name would be different. Also Address, Home Phone etc.
-
Misspelled First Name
- In this case patient’s First Name would be different.
- A simpler solution is to use fuzzy matching on First Name.
- But using a fuzzy matching on first name can lead to confusion in case of twins. The probability of twins sharing similar first name is more and in this case most of other data elements would be same.
- Also this can lead to confusion in case of similar sounding First Names if not used with care.
To implement these scenarios and identify/link correct patient, you must have some very strong match elements like SSN, Insurance Policy Number and Driver’s License Number in your repository and HL7 feed.